Practical Git: A Workflow to Preserve Your Sanity
Originally published: 2012-04-12
Last updated: 2015-04-27
Several years ago I made a blog post that questioned whether distributed version control systems were really generally useful. Its theme was “if the only reason that you need a DVCS is so that you can work on a plane, you don't really need a DVCS.”
I still believe that. A DVCS brings a lot of complexity to your development process, and given the depressingly large number of developers out there who can't be bothered to do an update and test before they commit, you're in for a world of pain if you suddenly make them go through the stage-commit-merge-push cycle of Git. For a single person or small, colocated team, I don't know if Git's benefits outweigh that pain. Especially if you're already comfortable with Subversion, which in recent versions has become a lot better at handling branches.
That said, almost all of my solo projects are maintained with Git, including this website. Partly, that's because I do work on a plane — or at least a disconnected laptop. And partly, it's because most of the people I work with use Git, and I don't want to have to remember which VCS I'm using for a particular project.
This article lays out what I feel are the best practices for getting started and using Git. It's based on a “broken branch” workflow, in which developers work on their own private branches and merge back into master (or a feature branch) only when work is complete. This generally follows the Linux development model, in which new features flows upstream into the master repository, and releasable software flows downstream to the consumers.
Step One: Create a Backup Repository
Git takes me back to the days of SCCS, when “rm -rf” wouldn't just delete your working directory, it would destroy the history file
as well. Of course, if you're in a team using Git, you can easily recover by
cloning from someone else. But if you're a solo developer, you'd better hope
that your backups are readable — you do regular backups of your
workspace, right? Subversion at least forces you to put your repository
somewhere out of the way, even if it's on the same machine.
It's easy to use git-push to maintain a personal backup repository. Step one is to create the repository in a location that you're not likely to accidentally destroy (at work, I use a separate machine; at home, a network-attached drive). If you created your working repository by cloning someone else, I suggest making a second clone for the backup. If you've just started the project, then either clone your working repo or use an OS-level tool such as rsync to copy the directory. I prefer the latter, as it means that the backup repository won't have an “origin” that you can accidentally push to.
The next step is to use git-remote to add the backup repository as a push target (“remote”) for your development repo. The URL bears some explanation: I connect via SSH, rather than using the Git server protocol. The reason for this is that the Git protocol requires each repository to have its own server. Which is fine for a single repository, but I'm going to assume that you'll have dozens of personal backups on a machine. In fact, I see no reason not to use SSH for all Git connections (and Subversion too).
git remote add backup ssh://foo.example.com/home/kgregory/Backup/repo
Next, you need to go to the backup repository and tell Git that it's OK to accept pushes. By default, Git won't let you push into the branch that's currently checked out in the remote repository. This makes a lot of sense if you're actually using the repository for work, because it means that the world will change underneath you if someone pushes. However, this repository is a backup repository, so we don't care.
There are a few ways to enable pushes. The simplest is to go into your backup repository and configure it as a “bare” repo: one without a working directory. Note that, once you mark a repository as bare, you won't be able to make commits from inside that repository — this is a Good Thing.
git config core.bare true
Now you can push your changes to the backup. If you're working on master, it's easy: you just tell Git to use the “backup” remote.
git push backup
But, as you'll see later, I don't like working on master. And if you start a branch in your working repository, you need to create that branch in the remote before you can push to it. So the first time you push you have to explicitly say what branch you're pushing to.
git push backup BRANCH
With A Team, Share The Backup
The “push me, pull you” nature of Git is nice for a couple of people sharing work. But I believe that a larger team — three people — needs a shared repository that holds the canonical version of their codebase. Otherwise you end up with “oh yeah, Harry has the latest copy, but he went on vacation and took his laptop.”
This shared repository should live on an machine that is accessible to all users, and is backed up regularly — just like the repository for a centralized version control system. Create and configure it just like the backup repo that I described above, and have all of your developers clone their working repositories from it. The result is the best of both worlds: the “I'm a unique snowflake” of Git, and the “someone else is taking care of backups” of centralized version control.
Have an Integration Czar
Who updates the shared repository? If you think of Git as “a better CVCS,” then the answer is everyone. And I think that Git has enough sanity-checking built in that this can work well: you can't push a conflict. But I think the Linux workflow is instructive, since Git exists to support it: there's a large web of people who make changes and submit them to module maintainers. These maintainers integrate the changes and send them on to Linus, who reviews them and updates the master repo.
If you're doing “branchy” development — such as an Agile
project with lots of independent stories — I believe that having one
person responsible for integration will make your lives easier. This person
ensures that everything merges cleanly, and works with the other team members
when it doesn't. She is also the only person who pushes to the shared repo,
as shown below (dashed lines are pulls, and solid lines are pushes).
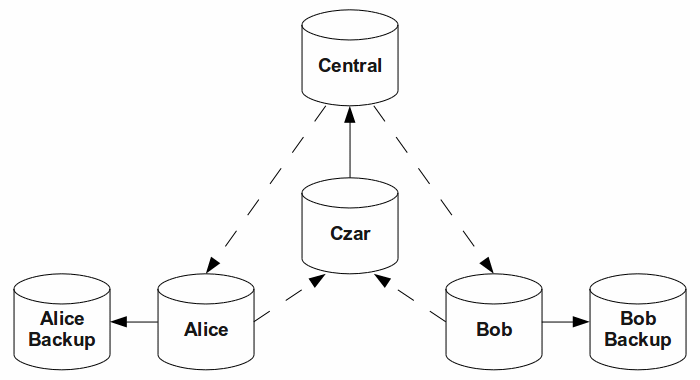
There's no reason to make one person “integration czar for life”; it can change with every sprint. I do think it's best if this person has the deepest knowledge of the codebase, because then most merge problems will get resolved quickly. Or you can pick the person with the least experience, as a way to give him that depth. Lastly, you can make integration a team sport, as GitHub does, using it as a chance for code reviews.
The take-away from this section is that integration is a big deal. I've heard a lot of talk about how Git makes merging easy, but my experience differs. If you have a bunch of people working on the same code, you will have merge conflicts, with or without Git. Accept that, and plan for them.
Each Separately-releasable Codebase Gets Its Own Repository
One of the myths of software development is that a single team is responsible for a single application. In my career, that has only been true for companies that produced a shrink-wrapped product, and those were rare. Usually, you have a corporate IT team that is responsible for multiple applications, or a single application that is split between front-end and back-end teams.
If you're coming to Git from Subversion, these divisions can get you into trouble. Subversion treats a repository as a forest of independent trees: work in one directory does not affect another, and you can apply tags to individual directories. In a lot of companies, there's only one repository. By comparison, Git treats the repository as a big graph of revisions, and a tag applies to the entire thing.
Because of this, it makes sense to give each project its own repository. But that leaves the problem of how to integrate these separate repositories.
One approach is to use Git's submodules. I think of submodules as being like Subversion externals, only not as flexible: the master project holds a reference to an explicit commit of the submodule, and the submodule appears to be a directory in the project. You can update that reference as needed (and the page linked above walks you through the process). But other than for fixed read-only views, I think they're more trouble than they're worth.
A better approach by far is to leverage your build tool. For example, in a Java shop I'd use Maven to create separate libraries as dependencies of the master project. If you have a continuous integration server and deploy builds to an artifact repository, you might never care that there are many pieces to your project.
Master is for Integration, not Development
CVS has conditioned developers to a bad habit: all work takes place on HEAD, and you cut tags and branches when ready to release. If you keep the same habit with Git, your merges will be a mess. This is a lesson that I learned the hard way, after forking a project on GitHub: I made a change, submitted a pull request, and then made another change. But when I went to submit a pull request for the second change, it contained both edits. Well, d'oh, that's because a pull request includes all changes since the point you forked.
With Git, the better approach is to create a branch for each piece of
functionality, and merge completed pieces into master or an integration
branch. This is how Linux development works: a lot of contributors send
patches to component maintainers, who integrate them and then send patches
on to Linus. One way to describe this practice, based on the way a revision
graph looks, is “fishbone integration.“
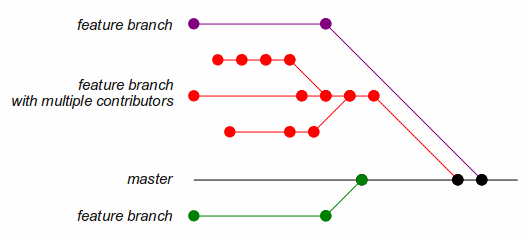
With fishbone integration, the central repository's copy of master only holds commits for completed work. Using a Scrum term, it is always in a “potentially shippable” state. More important to developers, it's stable: you can create a branch from master without worrying that a piece of half-implemented code will break under you.
Give Sprints Their Own Integration Branch
An Agile sprint is all about adding a measure of functionality to a stable (potentially shippable) product: at the end of the sprint, you should be able to disband the team, deploy the software, and get business value from it. During the sprint, the team works on a bunch of stories, which optimally have little connection with one another. This is a perfect use for Git branches: each story has its own branch. When the sprint ends, all of the stories will be done and can get merged.
Well, almost. In the real world, stories often have dependencies on one another: either direct (one story requires code from another) or indirect (one story isn't useful without the other). And at the end of the sprint, you might have stories that aren't completed. This makes merging directly to master a dicey business.
Instead, I recommend creating an integration branch from master at
the start of the sprint. Most stories will branch from integration at the
beginning; it's worthwhile to create a tag at this point. During the sprint,
some story branches will be merged back into integration to become the base
of other branches; some will be merged directly into other branches; and
some will just keep getting commits, with no end in sight. At the end of the
sprint you can merge the whole integration branch back to master,
or pick and choose completed stories. The revision graph will become quite
convoluted, but master remains in a shippable state.
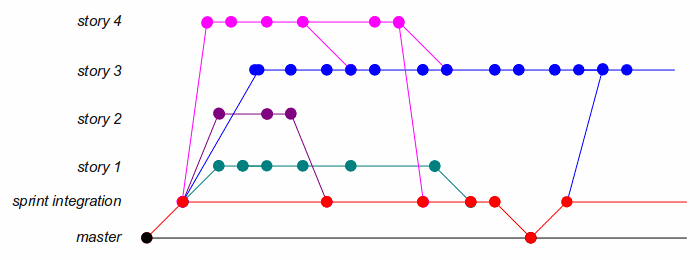
Another benefit of an integration branch is that it lets you practice continuous integration, which quickly uncovers incompatibilities between code written by different team members. However, to use continuous integration, you need a single place where the CI server can find the latest version of the codebase. And you need developers to regularly save their work to this location, which is in opposition to the distributed, branchy nature of Git. The integration branch provides this place.
Squash-merge Feature Branches
In my blog post on DVCS, I asked the rhetorical question “who cares about your commits, all we want to see is the result.” By default, Git and Mercurial merge a branch by applying all of the commits from that branch; they will forever after appear in the log. This can be painful, especially if your developers commit often: the changes for one feature may be spread out over a dozen commits.
In response to the post, my friend Jason pointed out that Git lets you “squash” the merge, leaving only a single commit on master. If there was one thing that pushed me toward Git rather than Mercurial, this was it.
git checkout master git merge --squash dev-branch git status git commit -m "merge current development branch"
Clean Up After Yourself
After the final merge from a branch, I like to delete the branch from my local clone so that I don't accidentally use it again.
git branch -D dev-branch
If you read the docs for git-branch, you'll see that you
can use lowercase -d or uppercase -D to delete a branch. The former verifies that the branch has been merged before
deleting it, the latter doesn't. Which means that if you squash your merges, Git
won't let you use -d. I believe it's easier to always use
-D, although you do give up some protection.
That still leaves the branch in your backup repository. I tend to leave old branches there “forever,” on the off chance that I need to look at a series of commits. However, if you want to clean out the backup, you need to use a rather non-intuitive command:
git checkout master git push backup :BRANCH
Some explanation: git-push actually takes a
refspec of the form “[+]LOCAL:REMOTE”, which pushes
the named local branch onto the named remote branch (and optionally overrides Git's
rule that prohibits pushes that require a merge). When using this command to delete
a branch, you're saying “push an empty branch into the named remote
branch.”
Some caveats: because Git is distributed, deleting a branch in one repository does not delete it in another. And because you can push a branch from one repository to another, you can re-create a deleted branch. Moreover, even if you delete the branch, the commits remain in your repository — they're just hard to find.
And a last point: if you squash merges, then the commit will be recorded as belonging to the integration czar. This makes the “blame” feature useless. On the other hand, the czar is responsible for making sure that an integration is successful, so perhaps “blame” is correct after all. And, since a good team practices collective code ownership, there's no reason to go pointing fingers anyway.
Use Stash to Handle Interrupts
It's 11 AM, and you're deep in the code; it won't even compile, much less pass tests. Then your boss walks up with a production problem that you need to fix. What do you do?
You could simply check in what you've got. It's just going to your local repo, so you won't have a horde of coworkers ready to string you up for breaking the build. But I think it's a bad idea to do this: once you check code in, you never know where it will end up. Someone else might take over your task and fetch your repository, and you're not helping him or her with half-written code. And you definitely don't want the habit of checking in broken code if you ever go back to a project that uses Subversion.
Another alternative is to clone your repository and make the production fix in the clone; this is the “Mercurial Way.” The problem here is that you're probably using an IDE that's configured for your normal working directories, and you'd have to reconfigure it to use the new repo. Meanwhile, your boss is still standing there, and she's getting impatient. And personally, I'm not happy having my work strewn over multiple repositories.
With Git, you don't have to take either of these routes. Instead, you stash your changes, and reload them when you're done with the interruption.
> git stash Saved working directory and index state WIP on dev: c724ea2 some random commit HEAD is now at c724ea2 some random commit
> # do your other work
> git stash pop
# On branch dev
# Changed but not updated:
# (use "git add <file>..." to update what will be committed)
# (use "git checkout -- <file>..." to discard changes in working directory)
#
# modified: bar
# modified: foo
#
no changes added to commit (use "git add" and/or "git commit -a")
Dropped refs/stash@{0} (6eb599bad229733f914c6b6f0da906b542ad8bfd)
You can create multiple stashes, and give them descriptive names. They're kept
in a stack, and each call to pop will retrieve the last set
of changes (you can also use apply to grab changes from the
middle of the stack). However, if you find yourself interrupted enough that you make
stashes on top of stashes, it's probably better to unstash your resume.
When Things Go Completely Pear-shaped, Create a Patch Series
Sooner or later, you will screw up. You'll create a branch from another
branch rather than master, or you'll do a pull rather than a fetch, or a push to
the wrong branch, or you'll stumble over one of the other many ways that Git
can trap the unwary. If you get into such a situation, git-format-patch can help get you out.
git format-patch master
This command produces one file for every commit since you last branched from
master, numbered in increasing order and named after the commit
message. You can use any revision specifier as the last argument: a tag, a
commit hash, or origin, which gives you all changes since
you created the branch (useful with the “fishbone” branching
strategy, where you create branches from branches).
If you've made a simple mistake, such as creating a branch from the wrong
starting point, then git-am is the way to recover. Create
a new branch from the correct starting point, move the patches that you want to
apply into a directory (here I use /tmp/patches), and
you're good to go.
> git checkout master Switched to branch 'master'
> git checkout -b dev-patched Switched to a new branch 'dev-patched'
> git am /tmp/patches/* Applying: add argle to foo Applying: add bargle to foo Applying: add wargle to foo
Alternatively, you can apply patches one at a time, using git-apply.
> git apply /tmp/patches/0001-add-argle-to-foo.patch
> git status # On branch temp # Changes not staged for commit: # (use "git add <file>..." to update what will be committed) # (use "git checkout -- <file>..." to discard changes in working directory) # # modified: foo # no changes added to commit (use "git add" and/or "git commit -a")
Note that, unlike am, apply leaves
the changes uncommitted and unstaged. When making a complex set of changes, this
is a really nice feature, because it lets you take a second look at the changes
(and a test run!) before committing.
While patches are useful, they do have limitations. A patchfile contains context — lines from the original file — to help the patch program figure out where the changes go. So, if you have a series of changes to the same file, later patches might depend on context created by earlier patches. If this happens, and a patch fails, my best advice is to look at the patchfile to figure out how to edit the file explicitly; patch files are human readable, although it can be inconvenient to apply a lot of changes by hand.
Renaming and Deleting Branches (or, master is not sacred)
Taking the previous example one step further, what happens if you accidentally merge a lot of changes into master rather than an integration branch? Or even make one commit that you didn't want? If you haven't pushed the changes to your central repository, and just want to discard them, then git-reset is your friend:
> git log
commit 5d665223de61826f8c399ae46c5eb4e2ce1ab902
Author: Keith Gregory <contact@kdgregory.com>
Date: Mon Dec 1 08:15:20 2014 -0500
add bargle to foo
commit 4232507ffe899acfa58163f77c4d6f4b49bf0a99
Author: Keith Gregory <contact@kdgregory.com>
Date: Mon Dec 1 08:15:13 2014 -0500
add argle to foo
commit 1b620debc84ebbbb0217e36cf5e8e0b9e5b5fc28
Author: Keith Gregory <contact@kdgregory.com>
Date: Mon Dec 1 08:14:57 2014 -0500
initial commit
> git reset --hard 4232507ffe899acfa58163f77c4d6f4b49bf0a99 HEAD is now at 4232507 add argle to foo
> git log
commit 4232507ffe899acfa58163f77c4d6f4b49bf0a99
Author: Keith Gregory <contact@kdgregory.com>
Date: Mon Dec 1 08:15:13 2014 -0500
add argle to foo
commit 1b620debc84ebbbb0217e36cf5e8e0b9e5b5fc28
Author: Keith Gregory <contact@kdgregory.com>
Date: Mon Dec 1 08:14:57 2014 -0500
initial commit
Beware that the commits still exist in your repository, although they won't be easily accessible and won't be included in a push. If those commits contain sensitive information such as passwords, and you're paranoid about security, you might want to throw away your local clone to prevent accidental disclosure (after preserving the commits that you want to keep, of couse).
As an alternative, you can delete and re-create the entire branch. I think
reset is a better choice for local changes, but the ideas
here carry through to making changes to your shared repository, which I'll
describe below.
The basic process is to check out a specific revision, which creates a “detached head”: your current working directory isn't tied to any branch. Then you can delete your old branch (here I use master, just to show that it isn't sacred) and create it anew. The last step ensures that subsequent pushes and pulls from the new master branch interact with master on the origin repository.
> git checkout 4232507ffe899acfa58163f77c4d6f4b49bf0a99 Note: checking out '4232507ffe899acfa58163f77c4d6f4b49bf0a99'. You are in 'detached HEAD' state. You can look around, make experimental changes and commit them, and you can discard any commits you make in this state without impacting any branches by performing another checkout. If you want to create a new branch to retain commits you create, you may do so (now or later) by using -b with the checkout command again. Example: git checkout -b new_branch_name HEAD is now at 4232507... add argle to foo
> git branch -D master Deleted branch master (was 82e7f99).
> git checkout -b master Switched to a new branch 'master'
> git branch master --set-upstream origin/master Branch master set up to track remote branch master from origin by rebasing.
WARNING: what follows can damage your central repository. Pay attention to what you're doing, and have a backup.
OK, what if you've pushed master with the bad changes? In this case, you need to remove the bad branch on the server and push your good branch. To do so, you use git-push with a refspec:
git push REPOSITORY LOCAL:REMOTE
REPOSITORY is the name of the remote repository that you're
pushing to; it's normally origin. LOCAL is the name of the branch in your local (working) repository, and
REMOTE is the name of the branch in the remote repository.
You can push any local branch to the remote with any name you like, although Git
will prevent you from overwriting an existing branch with incompatible changes
(although you can override this too).
You've already seen how to delete a remote branch: omit the LOCAL part.
git push REPOSITORY :REMOTE
Putting this together, the following two commands delete the master branch in your remote (origin) repository, and replace it with the master branch in your local repository.
> git push origin :master To /tmp/base_repo - [deleted] master
> git push origin master:master Total 0 (delta 0), reused 0 (delta 0) To /tmp/base_repo * [new branch] master -> master
As with deleting branches locally, the commits remain in the repository. If you've accidentally committed sensitive information, deleting the branch won't protect that information (although it will make it harder to find).
Working with GitHub
As public source repositories go, GitHub is about as good as it gets. It's easy to create and fork repositories, you can see a graphical view of the state of all forks and branches, there's an integrated issue tracker, and it's easy for an organization to control access to its repositories. As long as you're comfortable with storing your source code outside of your corporate data center, I think it's a great way to host your repositories.
GitHub promotes a particular workflow, one that is used for GitHub development itself. It's similar to what I've written above: master is for working code, branches get created for every feature, and developers push back to the central server “constantly.”
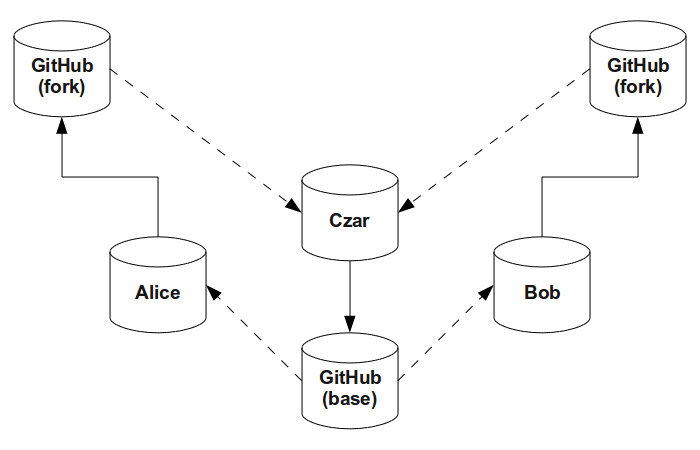
The picture below is a modification of my workflow to incorporate GitHub. As
with the earlier picture, dashed lines are pulls (or fetch/merge) and solid
lines are pushes. Each developer has his or her own fork of the master,
which serves as their backup repository. In a change from my previous picture,
this fork — rather than the developer's working repository — is
what the integration czar pulls from. This provides a nice level of isolation
for the working repo: a developer can push the specific changes that she wants
to integrate.
One interesting feature of GitHub is the “pull request” — and it's one that I think gets misused. It's a great feature: you make some changes, push them to your repository, and submit a pull request. The owner of the base repository gets notified of your changes, and can easily review them. Even better is that a pull request refers to the branch where you made the changes, so if you make more changes on that branch, the pull request reflects them. You can even submit a pull request between branches in the same repository, which is a nice way for teams to pass work around.
So why is it misused? Because in most cases integration is a simple button press. I strongly believe that you should at least do a test build before committing code to your master or integration branches, and the one-button merge bypasses that step. Plus, pull requests aren't squashed; if you don't want to see a lot of working commits, developers have to make an explicit “merge” branch with a single commit.
That said, I think that pull requests are a great tool for communication and code review — and reading between the lines of the Scot Chacon post that I linked above, that's how the GitHub team uses them. So by all means, create pull requests, just merge them manually.
Some Useful bash Functions
I use bash as my development shell, and I create shell functions to handle small, commonly repeated tasks. Here are a few of the ones that I use with Git.
Create or checkout a branch
If you use a lot of branches, this function is an easy way to switch between them and create new ones as needed. You can invoke it in two ways:
- branch
- Returns name of the branch that you're currently using.
- branch HNAME
- Checks out to the named branch. If it doesn't exist, switches to master, then creates and checks out the named branch. This avoids the mistake of creating one development branch based on another, but you must update it whenever your integration branch changes (because it should be the base for new development branches, rather than master).
function branch
{
if [ $# == 0 ] ; then
git branch | grep '^\*' | sed -e 's/.* //' ;
elif git branch | grep -q " $1\$" ; then
git checkout $1
else
git checkout master
git checkout -b $1
fi ;
}
Push the current branch
As you might guess from the sections on using backup and shared repositories (and the upcoming “you can push anywhere”), I push a lot. And any given branch might not have a dedicated upstream location. So, this function takes over from git-push. It can be invoked in three ways:
- push
- Pushes the current branch to the like-named branch on
origin, creating the remote branch if necessary. - push REMOTE
- Pushes the current branch to the like-named branch on the named remote, again creating it if necessary.
- push REMOTE NAME
- Pushes the current branch to the named branch on the named remote (I don't use this very often).
function push
{
src=`branch`
if [ $# == 0 ] ; then
git push origin ${src} ;
elif [ $# == 1 ] ; then
git push $1 ${src} ;
else
git push $1 ${src}:${2} ;
fi ;
}
Pull Updates to Branch
Without an assigned upstream branch, pulling can also be a chore. This function
is the counterpart to my push function.
- pull
- Pulls the like-named branch from
origininto the current branch. - pull NAME
- Pulls the named branch from
origininto the like-named branch in the current repository, creating it if needed.
You'll note that I don't have an invocation to pull a named branch from
an arbitrary repository. When I first created this function it would do
that, and I assumed that it would be useful for the integration czar.
However, in practice I much prefer fetch followed by
merge when pulling branches from arbitrary repositories.
function pull
{
if [ $# == 0 ] ; then
src=`branch` ;
git pull origin ${src} ;
elif [ $# == 1 ] ; then
branch $1
git pull origin $1 ;
else
echo "usage: pull [BRANCH]" ;
fi ;
}
Remove a Branch
This function is for cleanup once you've merged a branch: it removes a named branch, both in the local repository and in the origin. Yes, it's dangerous; pay attention to what you're typing.
function rmbranch
{
git checkout master
git branch rm -D $1
git push origin :$1
}
A Last Thought: You Can Push Anywhere
My “a-ha!” moment for Git came when working through the Heroku tutorial:
$ git push heroku master Counting objects: 67, done. Delta compression using up to 4 threads. Compressing objects: 100% (52/52), done. Writing objects: 100% (67/67), 86.33 KiB, done. Total 67 (delta 5), reused 0 (delta 0) -----> Heroku receiving push -----> Rails app detected ...
I pushed my repository to the Heroku server, and it automatically deployed. “Big deal,” you say, “that's just a repository hook; even CVS has repository hooks.” Yes, but it's a repository hook that I control, simply by choosing a particular remote repository.
For those of you who are lost: repository hooks are programs that run when
you interact with the repository — usually when you check in files.
One common hook is a validation of the commit message, forcing developers
to type “foo” rather than an empty line. You can also use hooks
to kick off an integration build, or prevent users from making updates to
files in a Subversion tags directory.
On centralized source-control systems, there's a single set of hooks, running on the single server. While you can jump through hoops to get different behaviors (eg, one user's commits trigger a CI build, others' don't), that's a lot of work. And it's risky: if you screw up a pre-commit hook, your developers won't be able to check-in their work.
Git, however, lets you push to multiple repositories, and each repository can have its own hooks. So if you push to the “ci” repo, you start a build on the continuous integration machine; if you push to the “qa” repo, you're making a new build available for your testers. And so on. You're limited only by the number of repositories that you want to create, and Git's refusal to push a commit that isn't a descendant of the current head.
For More Information
For details on the various things you can do with Git, take a look at the Git Community Book. I think that it's better organized than the official User's Manual; its chapter on rebasing is a particularly good explanation of a topic that's often misunderstood and feared (not to mention misused).
For an in-depth discussion of branching strategies, you should read git-flow. It is similar to my approach of master / sprint / story branches, but adds branches for releases and hotfixes. Also, the diagrams are much nicer than mine.
Copyright © Keith D Gregory, all rights reserved